# Core Concepts
To achieve our goal of "build local, deploy everywhere", MLDOCK brings together docker and cloud SDK's to help you develop and put your model in the cloud. For extra convenience, MLDOCK throws in container templating and a self-standing container life-cycle runtime.
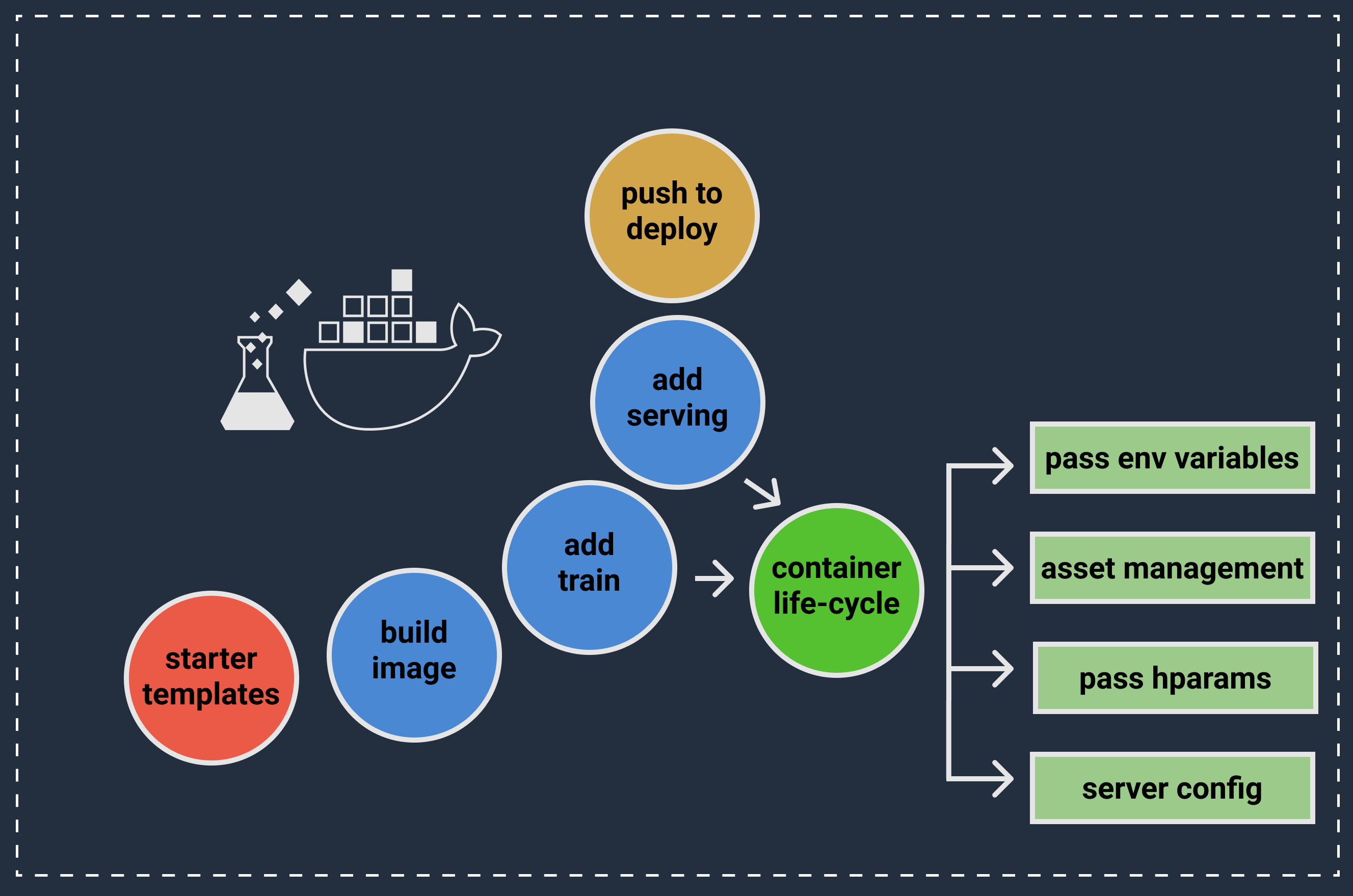
Everything said this helps to provide an iterable environment for developing locally and then allows you to build and deploy a container that runs on your chosen cloud container service.
# Local first development
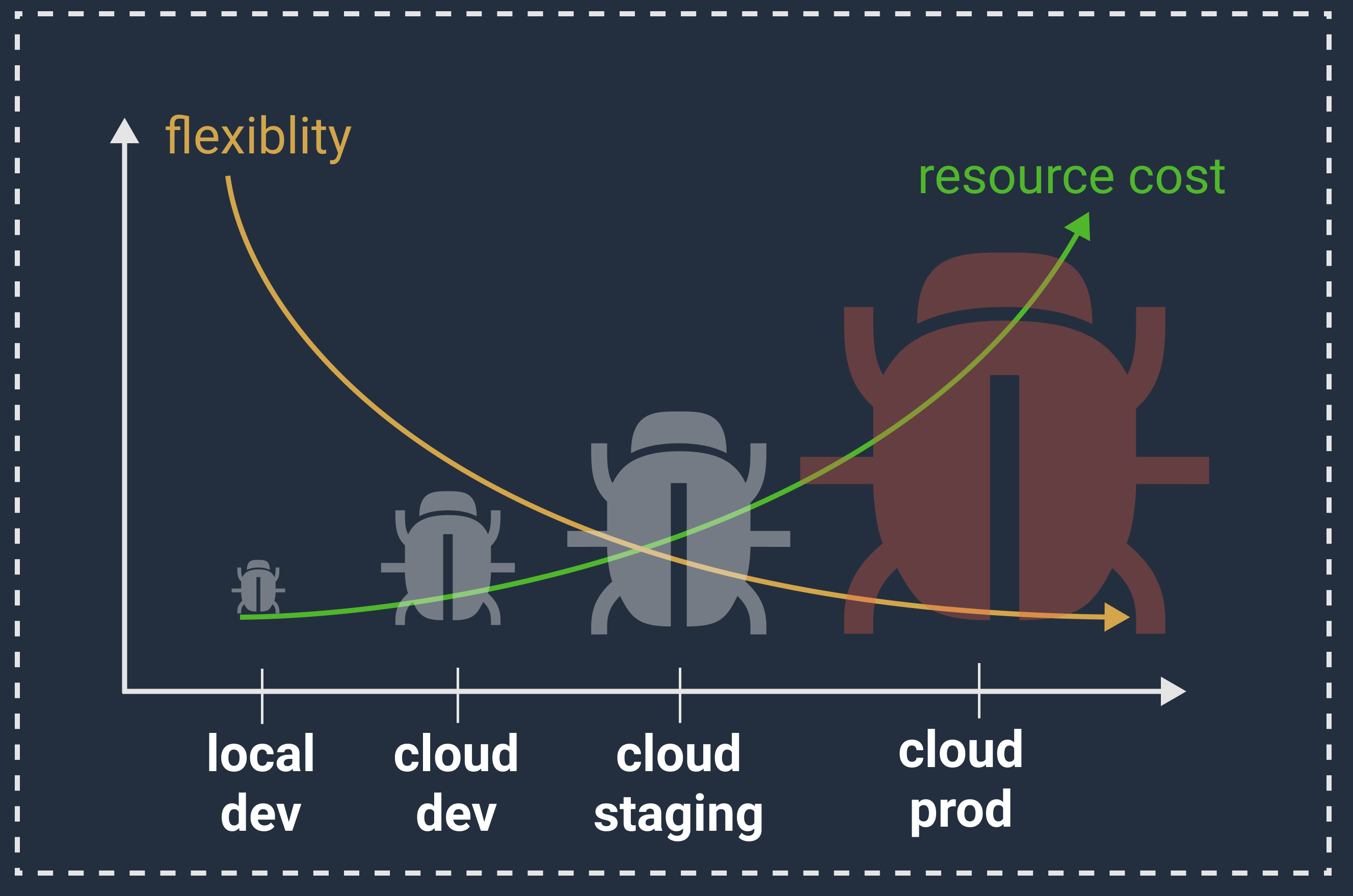
Starting with local development has many benefits, a few of which are:
- the cost of bugs
- the cost of resources
- loss of flexibility
TIP
Taking a note from app developers, think of validating our set up and our code in a CI/CD process. This will lead to less 🐛 bugs in production, leading to less fires 🔥
# Container Templates
Templates, better known as boilerplate code, allow developers to start quickly without having to write or copy and paste code from other sources like code blogs or stackoverflow. Put simply templates let you start from something and then only change what you need to make your code work.
MLDOCK leverages templates through the container initialization commands to build new containers. This becomes a power tool when given the fact that MLDOCK allows developers to create their own mldock-ready templates using templates create. Where an mldock-ready container basically requires a specific directory structure, namely the src/ and src/container/ directories.
A typical MLDOCK container project has the following project structure for code:
your_container_project_directory/
└── src
├── prediction.py
├── trainer.py
└── container/
├── Dockerfile
├── assets.py
├── executor.sh
├── prediction/
│ ├── nginx.conf
│ ├── predictor.py
│ ├── serve.py
│ └── wsgi.py
└── training/
└── train.py
TIP
MLDOCK allows you to create a new mldock-ready template from a working container. To find our more, check templates create.
# Container Life-Cycle Management
Similar to how your training script describes the steps taken to train a new machine learning model, a container has a life-cycle or set of steps that define when and how certain tasks should be done. Mldocks's standard container life-cycle can be described by the following steps:

We call it a design system because at it's core we provide a base environment class that can be inherited and extended. Allowing you to build new life-cycles for your requirements, including any new cloud platforms and just about any additional API calls and pythonic code.
# How MLDOCK supports container life-cycles
MLDOCK provides a base Environment() class that is used as a basis to all our container life-cycle workflows.
In short, this class sets up:
- container working directory at
/opt/ml. - Reads the environment variables to get
input, model, outputchannels set up and downloaded. - Reads the environment variables to find
hyperparameters.
We then leverage the Environment() class within the Assets.py script to create container life-cycle configuration classes i.e. TrainingContainer and ServingContainer. These classes that take an Environment() object at __init__ and have methods startup() and cleanup(). Together the environment and startup() and cleanup() methods are used to:
- prepare the container (as described above)
- download machine learning assets before the main script executes.
- upload machine learning assets once the main script is done executing.
# Supported Life-Cycles
Currently, we support to life-cycle management types out of the box, namely:
Environment()module based life-cycle management systemAsset.pyscripted life-cycle management system
TIP
For MLDOCK-based containers both the Environment() module and Assets.py are required and provided during the container init process. By default all they do is set up the appropriate container environment and file-system, but they can be extended to manage machine learning assets, provide platform specific integrations and run clean up tasks on the containers.
🚀 The possiblities are almost endless.
# Environment() module
This extends the base environment and adds special environment variables to manage the life-cycle stages. Users can define specific environment variables with prefixes that can be automatically discovered at container set up. There really two types of model assets, INPUT - downloaded from blob storage to training instance at task startup and OUTPUT - uploaded back to blob storage no task completion.
| ENV VAR Prefix Regex | Use Case |
|---|---|
MLDOCK_INPUT_CHANNEL_.* | Providing input assets for your model container runtime, e.g. Providing training data stored in s3 for your model, MLDOCK_INPUT_CHANNEL_TRAIN=s3://bucket/path/to/directory/containing/data |
MLDOCK_MODEL_INPUT_CHANNEL_.* | Providing a pre-trained model or previously trained model checkpoint for container runtime, e.g. If stored in s3 this could be: MLDOCK_MODEL_INPUT_CHANNEL_RESNET=s3://bucket/path/to/directory/containing/resnet/model |
MLDOCK_OUTPUT_CHANNEL_.* | Instructing mldock where upload resulting assets from training completion, e.g. If using s3 as your remote it could look like this: MLDOCK_INPUT_CHANNEL_TRAIN=s3://bucket/path/to/directory/to/upload/output/data |
MLDOCK_MODEL_OUTPUT_CHANNEL_.* | Instructing mldock where upload completed or trained model assets on training completion, e.g. If using s3 as your remote it could look like this: MLDOCK_MODEL_OUTPUT_CHANNEL_MYMODEL=s3://bucket/path/to/directory/containing/mymodel/model |
TIP
Please note in the local CLI all environment variables provided in the mldock.json configuration are prefixed with MLDOCK_ automatically before being passed in to the container environment. In production, you would do this prefixing manually. E.g. Say you wanted to pass a flag to disable CSV headers, called HEADERS=false, finding them in the MLDOCK container would mean looking for MLDOCK_HEADERS. This just makes sure that ENV VARS for both MLDOCK Environment Variables and the Cloud Platform (Sagemaker, etc) Environment Variables can coexist.
# How to use the Environment() workfow
To use any of the above input, model or output channels, simply add an appropriate channel regex to your environment variables with your given remote path as key. The machine learning assets will be downloaded and uploaded according to your current Environment() class i.e. the AWSEnvironment() treats Amazon S3 as your remote and will fetch your machine learning assets from your Amazon S3 filepath.
# Asset.py script
Assets.py is a script provided to define your container life-cycles and instantiate your environment and other shared assets for training or prediction tasks.
TIP
As an advantage of this Assets.py design, when you create your container life-cycles by extending the base environment you can use python to set out any additional tasks used during either startup or cleanup steps which are called before your script and on final after your script execution.
# How to use the Assets.py workfow
Using python, extend your TrainingContainer() and ServingContainer() to add additional tasks that mldock should execute when running startup() and cleanup() methods.
# Stages to support different workflows
Stages provides the developer with ways to design different workflows for production, development and testing. MLDOCK_STAGE environment variable is pulled in your container and allows your to run different container startup() and cleanup() workflows according your stage.
Extending the Assets.py workflow, we can now bring in MLDOCK_STAGE to allow the developer to fetch data or upload data to different places.